Ideation: Ausgesperrt – Störungen remote erkennen
Mit dem Ausbruch der Corona-Pandemie und dem damaligen Lockdown ergab sich für unser IT-Team eine neue Herausforderung. Wir verfügten bereits über eine VPN-Infrastruktur. Diese konnte skaliert werden und erlaubte uns, relativ reibungslos ins Home-Office zu wechseln.
Unsere existierenden, lokal betriebenen Monitoring-Lösungen (via OpenNMS) meldeten uns im IT-Team schon zu diesem Zeitpunkt aktuelle oder sich ankündigende Störungen. So konnten wir oft pro-aktiv agieren und Probleme beseitigen, bevor sie zu Ausfällen führen. Ziel ist es beispielsweise, Probleme eines Build-Servers zu beheben, bevor unsere Teams in der Entwicklung diese überhaupt bemerken.
Eine funktionierende Internetanbindung wurde durch die gestiegene Remote Arbeit noch entscheidender. Ein Ausfall unserer Internetverbindung führt dazu, dass Team-Mitglieder im Home-Office unter Umständen nicht mehr arbeitsfähig sind. Zudem erhalten wir im IT-Team dann von unseren Monitoring-Lösungen auch keine Benachrichtigungen mehr.
Störungen können daher eine Weile unentdeckt bleiben und erst bemerkt werden, wenn Anwender die Systeme nutzen wollen. Dies führt zu Reibungsverlusten in unseren Teams und auf allen Seiten zu einem erhöhten Stresslevel. Daher wollten wir im IT-Team über einen Ausfall möglichst schnell und aktiv informiert werden.
Im Jahr 2020 hatten wir hierfür noch keine Lösung.
Requirements: Blinder Fleck - Was brauchen wir?
Für die korrekte Minimal-Funktion unserer Infrastruktur ist eine gewisse Kette von Systemen ausschlaggebend. Diese Kette besteht aus folgenden Komponenten:
- Systeme unseres Internetanbieters
- Unser (Breitband-)Modem
- Unsere äußere Firewall (vor der DMZ)
- Unsere innere Firewall (hinter der DMZ) mit einem HTTP-Proxy
- Unsere Switches, die unser Rechenzentrum mit den Büroräumen verbinden
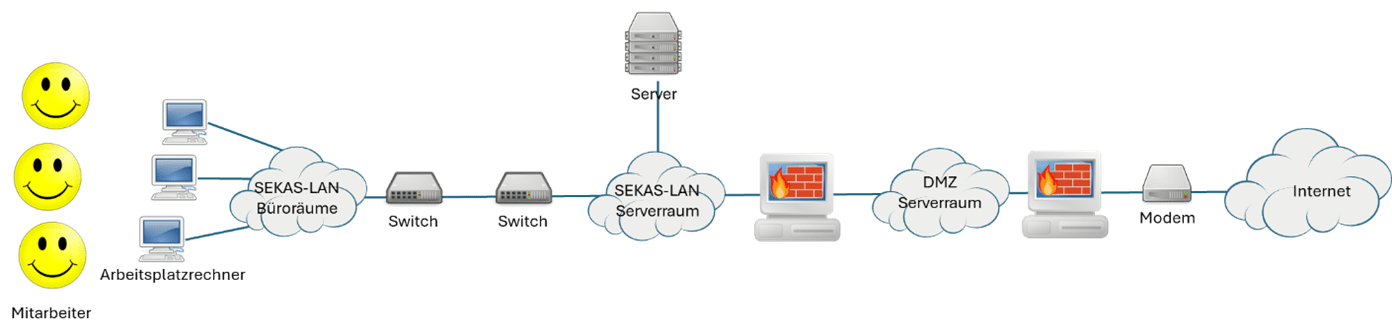
Wenn all diese Systeme funktionieren, sind Rechner innerhalb unserer Infrastruktur in der Lage, Verbindung mit dem Internet aufzunehmen. Unsere Nutzer sind grundlegend arbeitsfähig – egal ob vor Ort oder aus dem Home-Office heraus.
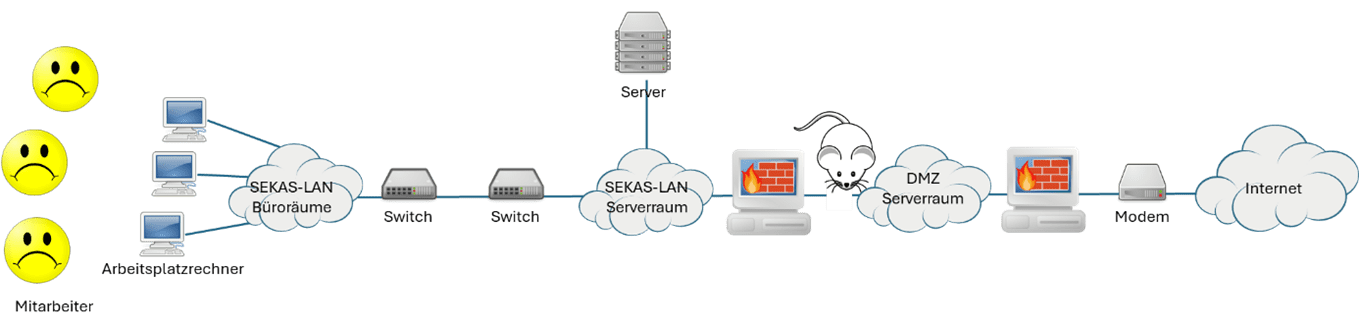
Störungen in der Internetanbindung wurden uns aber früher nicht automatisch aktiv gemeldet. Wir bemerkten dies nur, wenn wir selbst versucht haben, uns mit der SEKAS Infrastruktur zu verbinden bzw. diese zu nutzen.
Market Research: Gibt es so was nicht schon?
Als ich damals auf der Suche nach einem geeigneten Monitoring-System war, das unsere Anforderungen erfüllt, musste ich feststellen: Es gibt viele Anbieter und viele Open-Source-Lösungen im Bereich IT-Monitoring. Es war jedoch nichts zu finden, das auf unsere Anforderungen passte. Es gab Systeme die
- nur funktionierten, wenn man externen Systemen Zugriff auf die eigene IT gibt,
- für die Notifizierung eine funktionierende Internetverbindung brauchten,
- viel zu komplex für unsere Zwecke waren,
- zu teuer waren.
Ich beschloss also, ein möglichst einfaches System selbst zu realisieren. Ich dachte mir: „Das kann ja nicht so kompliziert sein. Ein bisschen Cloud-Infrastruktur, ein bisschen lokaler Agent. Los geht’s.“
System Architecture: Mal schauen was AWS so bietet
Für mich war das eine gute Gelegenheit mich mit AWS (Amazon Web Services) zu beschäftigen. Wir hatten bei SEKAS schon mit GCP (Google Cloud Platform) gearbeitet und hatten auch bereits Erfahrungen mit Microsoft Azure. AWS war für mich persönlich aber Neuland. Ich begann also, mich zu informieren, was AWS so bietet, das in diesem Szenario nützlich sein könnte.
Es zeigte sich: sehr viel!
Das Hauptproblem war, aus den vielen Angeboten, die auf AWS zur Verfügung stehen, die für die Aufgabe sinnvollsten herauszusuchen. Damit galt es dann eine geeignete Architektur zu definieren. Hierbei passiert es schnell, dass man den Wald vor lauter Bäumen nicht mehr sieht. Zur Veranschaulichung: Man findet allein zwei Dutzend Datenbankprodukte, die AWS anbietet. Mir kamen erste Zweifel, ob ich hier mit Kanonen auf Spatzen schieße. Lässt sich wirklich eine einfache Lösung für das Problem aufbauen, die am Ende nicht viel zu komplex wird?
Daher zunächst nochmal einen Schritt zurück und grob überlegen, was die Hauptkomponenten sind. Ich wusste, das System soll ungefähr so aussehen:

System Design: Wie funktioniert das Ganze?
Zunächst musste untersucht werden, welche dieser Services für meine Anwendung in Frage kommen. Inwieweit entsprechen sie unseren Anforderungen und gibt es irgendwelche Kostenfallen?
Ich bin dann bei dem folgenden groben Design gelandet:

Implementation: Steckt der Teufel im Detail?
Die Node.js App ist relativ einfach. Sie besteht aus 83 Zeilen Typescript-Code, der in einem konfigurierbaren Intervall (bei uns alle 5 Minuten) HTTPS POST-Requests an einen Cloud-Endpoint schickt. Der Request enthält lediglich den Hostnamen des Rechners und einen geheimen API-Key. Die eigentliche Applikationslogik macht circa die Hälfte des Source-Codes aus. Die andere Hälfte enthält Dinge wie Logging, Behandlung von Kommandozeilenargumenten und Setupfunktionen, damit der Code als Windows-Service installiert werden kann.
Der Endpoint, an den die Node.js App die Requests schickt, wird von dem AWS API-Gateway zur Verfügung gestellt. Das API-Gateway ist so konfiguriert, dass Requests an den iAmAlive-Lambda-Service weitergeleitet werden. Außerdem werden Requests geloggt und ein Rate-Limiting ist eingerichtet, um zu verhindern, dass durch eine Fehlkonfiguration hohe Kosten entstehen können. (Dunkle Wolken werfen ihre Schatten voraus …)
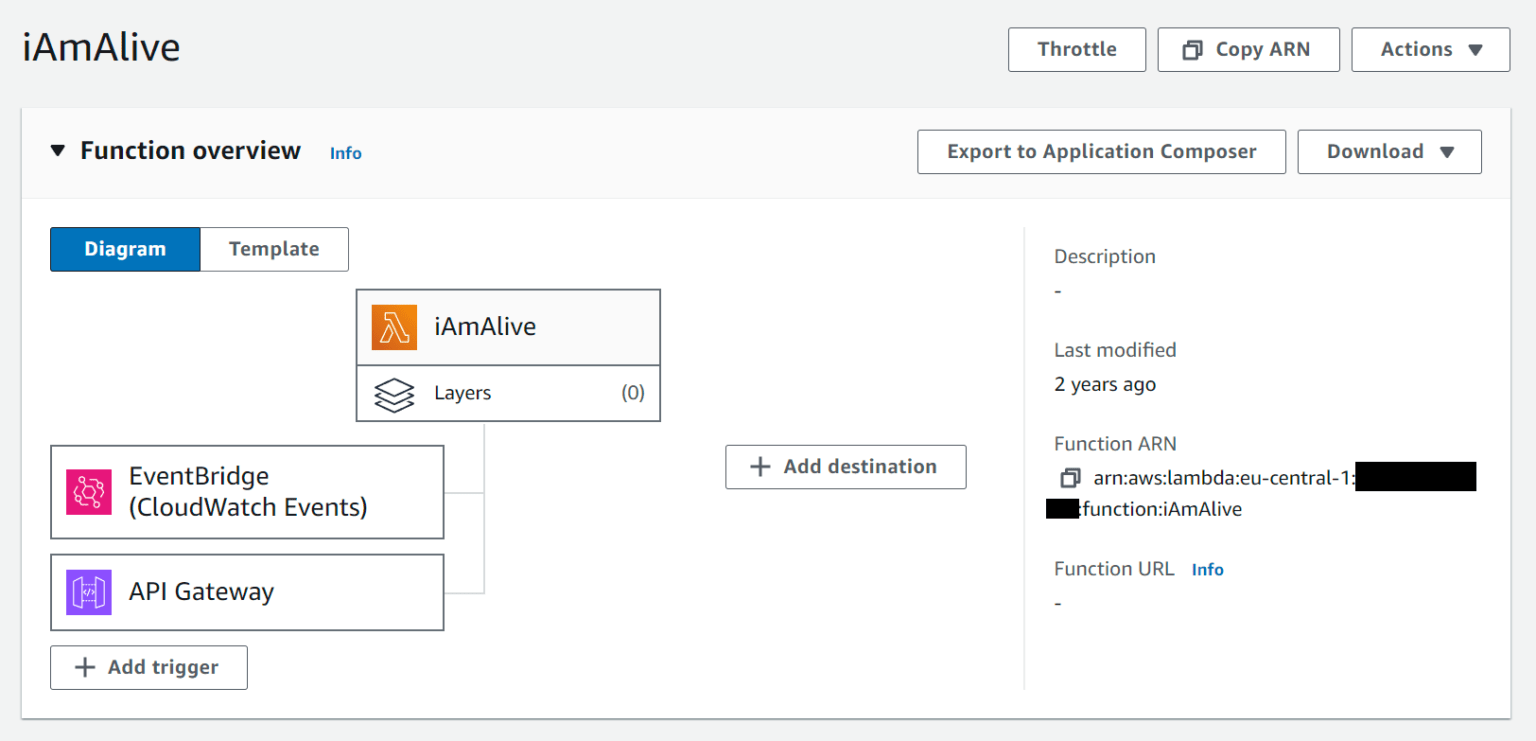
Die erste Hälfte der Lambda-Function wird durch die Post-Requests der Node.js App (via API-Gateway) getriggert. Sie nimmt den Hostnamen aus dem Request und aktualisiert die DynamoDB Datenbank entsprechend. Der Hostname ist dabei der Primärschlüssel. In die DB-Zeile für den Host wird in der Spalte lastSeen die aktuelle Urzeit eingetragen.
Die zweite Hälfte der Lambda-Function wir durch Cloud-Watch regelmäßig (alle zwei Minuten) ausgelöst. Für alle Zeilen in der DynamoDB wird folgende Logik durchlaufen:
- Ist es länger als 10 Minuten her, dass sich der Agent gemeldet hat?
- Falls wir für diesen Rechner schon alarmiert haben, stellen wir sicher, dass nicht unnötig oft alarmiert wird.
- Falls angebracht alarmieren wir, wobei folgende Daten relevant sind:
- Name des Rechners
- Zeitpunkt, wann sich der Agent zuletzt gemeldet hat.
- Andernfalls (Agent hat sich in den letzten 10 Minuten gemeldet)
- Falls der Rechner davor als „abwesend“ gemeldet wurde, senden wir eine Benachrichtigung, dass für diesen Rechner wieder alles OK ist.
In der DynamoDB liegen als Grundlage für diese Logik immer folgende Werte:
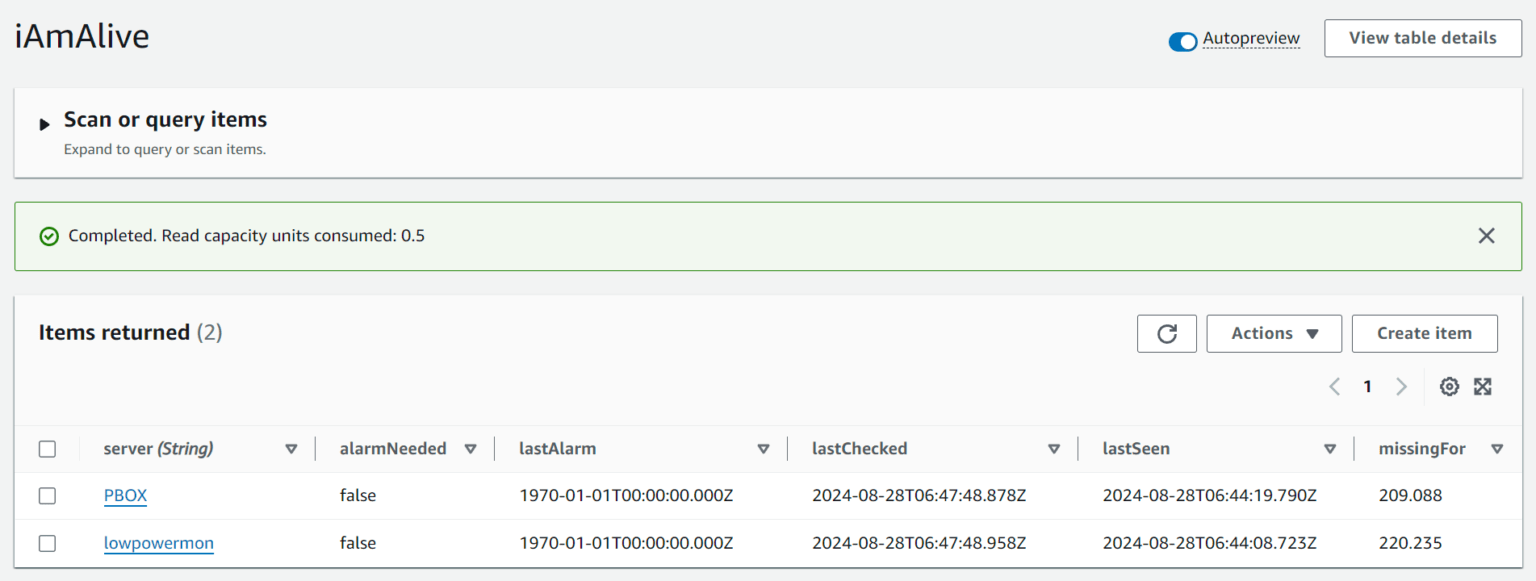
- server: Name des Rechners
- alarmNeeded: Muss für diesen Rechner alarmiert werden?
- lastAlarm: Wann wurde für diesen Rechner zuletzt alarmiert?
- lastChecked: Wann wurde dieser Rechner zuletzt überprüft?
- lastSeen: Wann hat sich der Agent zuletzt gemeldet?
- missingFor: Wie viele Sekunden ist es her, dass sich der Agent zuletzt gemeldet hat?
Hierbei ist die Information missingFor redundant, wurde aber für Debugging- / Logging-Zwecke bewusst eingeführt.
Wenn tatsächlich eine Alarmierung (oder Entwarnung) gesendet werden soll, wird ein entsprechender Meldungstext zusammengebaut. Die Meldung wird über AWS SNS (Simple Notification Service) als E-Mail verschickt. Zudem erfolgt eine Benachrichtigung via Teams Webhook in unseren IT-Infrastruktur/Status-Kanal. Das Senden via SNS nutzt dabei die AWS.SNS-API direkt aus der Lambda-Funktion. Der Teams Webhook wird über einen HTTPS-Request aufgerufen.
Mein positives Zwischenfazit zu diesem Zeitpunkt:
„Viele AWS-Dienste. Viel Konfiguration. Wenig Code.“
Den befürchteten Teufel im Detail hatte ich bis dahin zumindest noch nicht gefunden.
Deployment: Wir Starten! Es wird spannend …
Am 15.5.2020 habe ich iAmAlive ausgerollt und scharf geschaltet. Zunächst fehlte die Notifizierung via Teams-Webhook, aber das habe ich später nachgerüstet.
Die erste (mit Absicht provozierte) Ausfallnachricht via SNS-E-Mail sah so aus:

Und die zugehörige Entwarnung so:

Ich hatte das damals mit zwei Agenten auf zwei zu überwachenden Rechnern aufgesetzt. Einer dieser Rechner war ein Windows-Server in unserem Rechnerraum. Der andere war mein Arbeitsplatzrechner im Büro. Das bedeutete, dass mein Arbeitsplatzrechner rund um die Uhr durchlaufen musste. Für den Anfang war das in der Corona-Notsituation akzeptabel, konnte aber kein Dauerzustand bleiben.
Wir konnten so aber definitiv erst einmal in die Nutzungsphase starten.
Going Live: Mission completed – aber erfolgreich?
Erste Erfahrungen waren durchaus positiv.
Schon bald gab es einige Situationen, in denen wir tatsächlich Infrastrukturprobleme hatten und darüber frühzeitig benachrichtigt wurden.
Erste Alarme: Problem erkannt – Gefahr gebannt
Eines Morgens erhielt ich – auf dem Weg zu meinem ersten Kaffee – eine Alarmierung auf meinem Handy. Noch schnell den Kaffee genossen, um wirklich wach zu sein. Dann schlossen wir uns im IT-Team kurz. Wir klärten, wer möglichst frühzeitig in der Firma sein und das Problem analysieren konnte. Diese Analyse offenbarte damals eine Schwachstelle unserer externen Firewall. Diese schien ein Problem mit der Verwaltung von UDP-Anfragen zu haben. DNS-Requests ins Internet funktionierten nicht mehr zuverlässig. Das verursachte diverse Probleme in unserer Infrastruktur. Zudem konnte iAmAlive sich nicht mehr in der Cloud melden, sodass eine Alarmierung ausgelöst wurde. Ein Reboot der Firewall löste das Problem, noch bevor die Entwickler-Teams aufgewacht waren oder ihr Frühstück beendet hatten 😉 . Die erste echte Nagelprobe hatte das System also bestanden.
False Positive: Houston, haben wir ein Problem?
Wir hatten insgesamt sehr wenige Fehlalarme, die sich normalerweise schnell klären ließen.
Beispielsweise führt unser System-Administrator gelegentlich Wartungsarbeiten durch. Er fährt dabei u.a. Systeme herunter, um Recovery-Images für unsere Disaster-Recovery zu ziehen. Diese Wartungsarbeiten führt er typischerweise abends durch, nachdem die Mitarbeiter das Büro verlassen haben. Ich sitze dann oftmals gerade beim Abendessen, wenn die Alarmmeldungen von iAmAlive eintrudeln. Meistens bekomme ich dann erst mal einen Schreck, bevor ich daran denke, dass die Wartungsarbeiten ja angekündigt waren.
Echtes Unbehagen befiel mich bei einem Vorfall in der Anfangszeit von iAmAlive im August 2020. Ich war gerade unterwegs, als eines Morgens die ersten Alarmmeldungen eintrafen. Nach hektischen Telefonaten stellte sich heraus, dass in unseren Büros alles tadellos funktionierte.
Ich war ziemlich verwirrt. Hatte meine Lösung doch noch ein gravierendes Problem? Hatte ich etwas übersehen und wir waren noch gar nicht am Ziel? Etwas verunsichert musste ich die Sache für den Moment liegenlassen. Ich beschloss aber die Sache näher zu untersuchen sowie ich im Büro sein würde.
Mit einer gewissen Anspannung setzte ich mich etwas später an die Analyse. Nach längerer Recherche fiel es mir dann wie Schuppen aus den Haaren. Es stellte sich heraus, dass ich Opfer meiner eigenen Vorsicht geworden war. Wie bei der Implementierung beschrieben, hatte ich im API-Gateway ein Rate-Limit gesetzt:
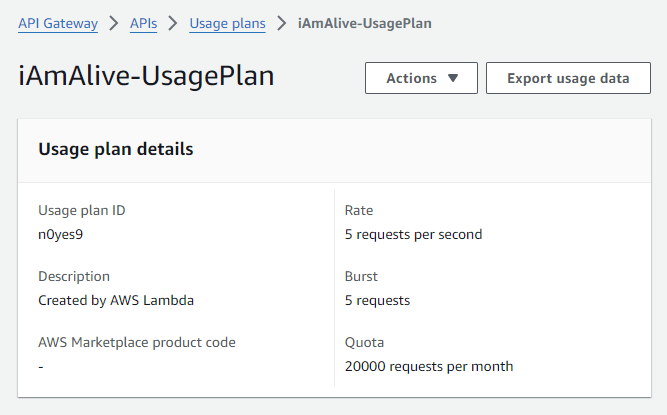
Da unsere Agenten alle fünf Minuten einen Request machen, kommen wir bei zwei Agenten auf maximal knapp 18.000 Requests pro Monat. Ich hatte also ein Limit bei 20.000 Requests eingerichtet. Anfang August hatte ich zum Test aber eine Zeitlang einen dritten Agenten laufen, der auch noch Requests machte. Am 28. August war dann das Limit von 20.000 Requests erschöpft und das API-Gateway leitete keine Requests mehr an die Lambda-Function weiter.
Der Grund, warum ich überhaupt solch ein Limit gesetzt hatte? In der Anfangsphase hatte ich große Bedenken, dass uns die Kosten für das System explodieren könnten. Speziell, wenn ein Agent Amok läuft und ungebremst Requests ausführt, könnte das böse enden.
Schön, wenn die eigenen Mechanismen dann funktionieren, selbst wenn man selber drüber stolpert.
Alles in Allem also zweifelsfrei: Mission Accomplished!
Maintenance: Verbesserungen im Laufe der Zeit
Über die Jahre gab es immer wieder kleine Ergänzungen und Verbesserungen.
Im Mai 2021 habe ich zum Beispiel zusätzlich zur Notifikation über E-Mail auch noch die Notifikation über Teams-Webhook implementiert. Beim Einrichten eines solchen Webhooks wird ein HTTPS-Endpoint erzeugt, in den Nachrichten via REST-Aufrufe eingespeist werden können. Microsoft kümmert sich dann darum, dass die Nachrichten in dem entsprechenden Teams-Kanal landen.
Ich hatte extra für den Teams-Webhook ein passendes Icon entworfen:
In der Anfangszeit wurden die Nachrichten auch mit diesem Icon präsentiert statt mit dem generischen Webhook Icon. Leider funktioniert das seit einiger Zeit nicht mehr. Ich werde jetzt nicht mehr forschen, warum das nicht mehr funktioniert. Microsoft hat die Webhooks abgekündigt. Daher muss ab 2025 sowieso eine neue Lösung via Workflows implementiert werden.
Ursprünglich liefen die iAmAlive-Agenten auf zwei Windows-Rechnern, einem Server und einem Arbeitsplatzrechner. Damit der Arbeitsplatzrechner nicht mehr rund um die Uhr laufen musste, habe ich einen Raspberry Pi beschafft. Da der Agent in Node.js implementiert ist, war es kein Problem, den Agenten auf dem Raspberry Pi zu starten. Ich musste lediglich eine systemd Service-Definition erstellen. Das läuft seitdem auch problemlos.
Eine wichtige Verbesserung im Juli 2022 war, ein ausführliches Logging in den Agenten zu implementieren. Das Logging schreibt die Informationen einfach in eine Log-Datei. Bei einem Ausfall sind diese Ausgaben sehr hilfreich. Wir können nun besser diagnostizieren, um was für eine Art von Problem es sich handelt.
Ebenfalls im August 2022 wurde die Lambda-Funktion von Node.js Version 12 auf Version 16 aktualisiert.
Man sieht – auch in diesem Umfeld gilt: So richtig fertig ist man nie.
Lessons learned: War das eine gute Idee?
Insgesamt ist iAmAlive ein voller Erfolg. Wir können uns im normalen Alltag darauf verlassen, dass wir es mitbekommen, wenn unsere Infrastruktur Zicken macht. Wenn die Anbindung an das Internet ausfällt, werden wir von iAmAlive benachrichtigt. Wenn sonstige Probleme bestehen, funktionieren unsere „normalen“ Monitoring-Systeme und benachrichtigen uns.
Für mich persönlich sorgt das enorm für Seelenfrieden. Wir hatten im Laufe der Jahre immer wieder Situationen, in denen wir von iAmAlive über Probleme benachrichtigt wurden. So konnten wir agieren, bevor unsere Mitarbeiter die Störung überhaupt mitbekommen haben.
Anfangs hatten wir etwas Sorgen, ob wir in irgendwelche Kostenfallen geraten. Daher hatte ich ja auch die Zahl der Zugriffe aus Sicherheitsgründen beschränkt (siehe oben). In unserer Konfiguration treten kaum nennenswerte Zugriffe und Kosten auf. Seit wir iAmAlive betreiben, liegen die AWS-Nutzungskosten für das System monatlich im einstelligen Cent-Bereich.
Für mich war die Verwendung der AWS-Dienste ein interessantes Erlebnis. Es ist spannend, für kleine Dinge aus dem Vollen schöpfen zu können. Ist es nötig, für eine Tabelle mit zwei Zeilen und 6 Spalten eine hochskalierbare, hochverfügbare verteilte Datenbank wie DynamoDB zu verwenden? Nein, natürlich nicht. Sie ist aber „einfach da“, wird von AWS betrieben und kostet uns weder Geld noch Aufwand. Die Verwendung über die API ist einfach und leicht zu lernen. Also: warum nicht?
Lambda-Functions (Serverless) ist auch so ein Thema. Es gab viel Hype zu dieser Technologie, aber auch Ernüchterung, da die Kosten explodieren können. Für eine Anwendung wie iAmAlive ist es ein Segen, keine dedizierte Infrastruktur aufsetzen zu müssen. Die Kosten für den Betrieb sind in unserem Fall kein Faktor.
Insgesamt war iAmAlive für mich ein spannendes Projekt. Das Tool konnte in der turbulenten Zeit der Corona-Pandemie und bis heute eine meiner Sorgen beheben. Die Entwicklung hat mir neue Einblicke in die Welt der Cloud-Infrastruktur beschert.
Das Ergebnis zeigt, dass auch kleinere Cloud-Lösungen umsetzbar sind. Dabei müssen – wenn man sich des Risikos bewusst ist – weder Komplexität noch Kosten explodieren.